
原文地址:Emergent Communication Through Negotiation
Abstract
这篇工作利用MARL (Multi-Agent Reinforcement Learning)来研究在谈判协商中的语言生成问题。文章设置了两种交流的protocol,第一种是和游戏本身内容高度相关的proposal,第二种是用于交换潜在信息的cheap talk。文章实验发现对于self-interested类型的agent来说,谈判过程不会导致语言的生成;而对于prosocial类型的agent来说,谈判过程生成了语言。文章的结论验证了“Cooperation is necessary for language to emerge”,即合作是语言生成的必须条件。
Introduction
文章的动机在于探索交流 (Communication)是如何产生的。“Given these basic requirements, an interesting question to ask is what task structures aid the emergence of communication and how different communication protocols affect task success.” 在这篇文章之前有很多工作通过referential games的设置研究指代问题,本文指出人类语言并不简单是一个指代工具,而且人类很多情况下的沟通是非完全合作性质的,因此本文研究的是在这些非完全合作情境中语言的出现。文章中关于指代问题的文章链接贴在下面,未来可以研究一下。
- Learning to communicate in a decentralized environment
- Multi-agent cooperation and the emergence of (natural) language
- Emergent language in a multi-modal, multi-step referential game
文章采用了一个经典的谈判问题The bargaining problem来作为研究的环境。文章认为,有效的交流在该问题中是非常关键的,因为agent需要通过交流传达出自己的desire,以及通过交流推断对方的意图。原先的工作主要用offer/counter-offer这样的bargaining game形式来做,但是没有研究emergent communication这样的问题。而MARL在最近的发展为研究这类问题提供了非常好的方法。“By repeatedly interacting with other agents learning at the same time, agents can gradually bootstrap complex behaviour, including motor skills and linguistic communication.”关于motor skills和linguistic communication的引用已经列在下面。
- Emergent complexity via multi-agent competition
- Multi-agent cooperation and the emergence of (natural) language
- Learning to communicate with sequences of symbols.
文章在bargaining问题设置了两个交流通道,第一种通道是proposal,第二种通道是cheap talks。在一对一的实验中,文章发现selfish agent可以通过proposal通道和对方agent达成相对合理的分割,但是selfish agent却没有办法利用cheap talks的通道;相反prosocial agent却通过cheap talks的通道生成了语言,为了更好地和对方沟通达成相同目标。第二组实验是针对一个社群的agent进行的,先前关于社群的工作有以下几个观察:
- cheap talk can have a significant effect on the evolutionary dynamics of the population. (Efficiency in evolutionary games: Darwin, nash and the secret handshake)
- cheap talk also influences the equilibria, stability, and basins of attractions. (Signals, evolution and the explanatory power of transient information.)
- unless trainned in a diverse environment, agents overfit to their specific opponent or teammate. (A unified game-theoretic approach to multiagent reinforcement learning.)
文章在这些观察上给出了自己的设置:一个agent去和不同等级的prosociality的agent进行交互的同时去identify and model other agents’ beliefs帮助谈判的成功。这一结果和基于Theory of Mind这篇文章的模型是相似的:boundedly rational agents can collectively benefit by making inferences about the sophistication levels and beliefs of their opponents (Game theory of mind).
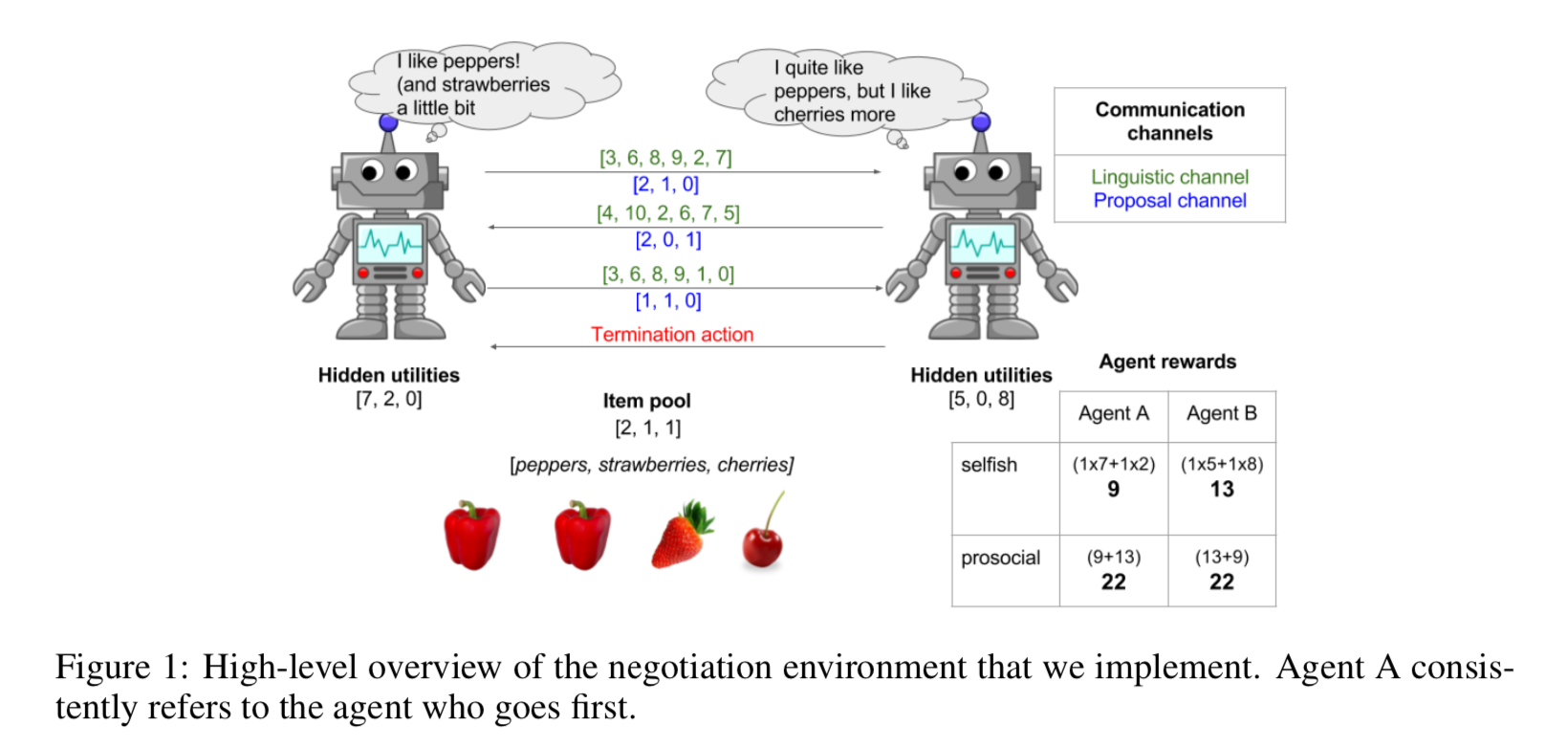
Game Setting
Negotiation Environment
基本设置有以下:
- 三种item:[peppers, cherries, strawberries]
- 每种item在[0,5]的整数区间内随机初始化数量
- 相互隐藏的utility function对应不同的agent对不同item的喜好程度,分布在[0,10]的整数区间内
- 每一次通信包括了proposal和cheap talk
- special action用于接受最近一次对方提出的proposal。如果接受的proposal为非法的(例如某个超出当前的最大数量)则双方同时获得0 reward
- 如果在最后一轮依旧没有协议达成,双方同时获得0 reward
- 最大协商轮数$N$不再是一个固定的自然数,而是一个在[4,10]整数范围内进行truncated Poisson distribution with mean 7的值。这么做是为了消除先手优势(先手方可以在最后一轮提出极大对自己有利的proposal)。这是参考了ultimatum game的问题进行的改进(An experimental analysis of ultimatum bargaining)。
但这里的问题就是:其实我们也可以给出一个根据概率分布的策略来实现先手对后手的优势,例如在第4轮前保持proposal不变,随着谈判向后进行再逐步严格proposal,因为在之后轮terminate的概率会变高,因此后手尽快接受proposal的意图也会更加明显。所以这里我个人认为只需要先后手依次进行就能够消除所谓的问题ultimatum bargaining的问题。
Communication Channels
Proposal channel就是一个提出的分割方案;Linguistic channel是本文对cheap talk这个沟通形式的一个具体方案,它在两个方面和Proposal channel不同:
- Non-bindingness: Messages sent via this channel do not commit the sender to any course of action, unlike directly transmitting a proposal which binds the sender to the proposal.
- Unverifiability: There is no inherent link between the linguistic utterance and the private proposal made, meaning that the agents could potentially lie.
文章关注的点在于:whether and under what circumstances the agents can make use of this channel to facilitate negotiation and establish a common ground for the symbols.
Agent Sociality & Reward Schemes
agent的社会性本质上是由奖励方案反应的,在本文中,prosocial agent就是为了最大化双方的共同价值,而selfish agent就是单纯地最大化自己的价值。在预期里,prosocial agent是需要communication的通道的因为他们需要交流各自的utility function才能达到总体的最大化。
Agent Architecture & Learning
每个时间步$t$, agent接受3个形式的input:
- item context $c^j=[i;u_j]$, 是item pool $i$ 和该agent的utility函数(也就是向量)
- utterance $m_{t-1}$, 是对方上一个时间步给的cheap talk
- proposal $p_{t-1}$, 是对方上一个时间步给的proposal
关于agent参数的modeling并不是很重要,无非就是一些LSTM罢了。而每个agent需要独立地优化以下objective function:
其中的$H(\pi_i)$是一个叫做entropy regularization term的东西,是为了鼓励agent在训练时去更多地explore,这一块的内容需要进一步学习。
Experiment
前两个实验的内容(Can self-interested agents learn to negotiate & Can prosocial agents learn to coordinate? )并没有特别有趣的,重点放在后面两个实验。
Analysis of Linguistic Communication
在self-interested agent和prosocial agent的协商实验中,通过分析symbol usage得出了以下结论:
- self-interested agent没有生成类似于自然语言一样的Zipfian distribution;而对于prosocial agent来说确生成了这样长尾效应的元组分布。
- 在这两方的协商中文章认为形成了一种类似于speaker-listener的交流方式,也就是说self-interested agent会倾听对方的给出的reward的信息,而不会泄露自己的utility。而prosocial会通过linguistic channel编码自己的信息告诉对方自己的utility从而达成合作。我对这个分析的怀疑在于:理性来说泄露自己的utility给一个完全self-interested agent来说是不会有反馈的,因为你只会帮助对方榨取自己的价值。只有一种情况有帮助:你utility高的item在对方的utility为0,对方才有让出利益的动机。这一点也需要验证。
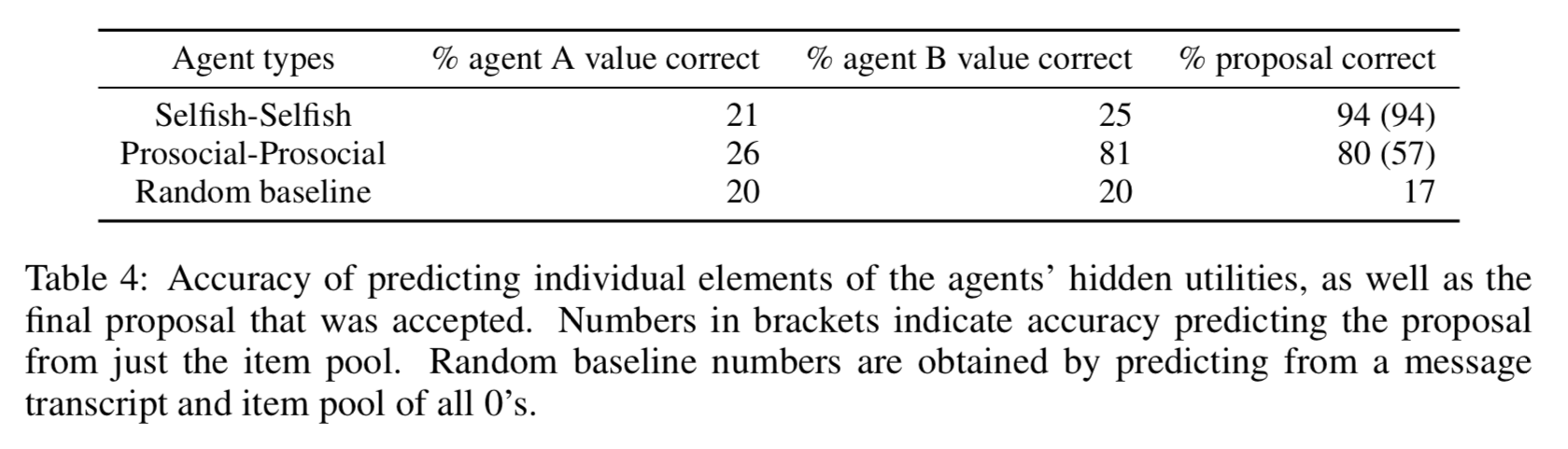
接着文章验证了在linguistic channel中有存在关于自身utility的关键信息,通过一个LSTM去编码解码linguistic channel的内容来预测utility的信息。结果是self-interested无法用LSTM去做合理的预测,而prosocial确实是含有语义信息的。但是疑问在于下图中的第二行为什么prosocial-prosocial的agent A也没有办法解码,文章没有给出解释。
同时另外一个值得研究的问题在于,self-interested agent如果在channel中学会了欺骗行为,那么是否意味着拿LSTM去预测正确的标签是不合理的?这是未来需要讨论的一点。
A Society of Agents
更加符合现实的情况是有一个社群的agents,并且每一个agent的亲社会性是不同等级的,因此一个agent为了最大化自己的目标需要学会去identify不同agent的亲社会性,判断其是否擅于合作。文章设置了10个不同亲社会等级的agent,通过固定某个agent,维护一个opponent embedding来实现对对手亲社会性的利用。发现opponent的行为属性能够完全反映在embedding向量中,以下的PCA降维可视化能够反映出这一点。

关于在community中的语言学现象,有以下的总结:
- In one of our experimental settings, a community of prosocial agents developed a language and were able to use this to achieve better negotiation success.
- Interestingly, the only situation when agents developed a language was when ID information was not provided.
- When prosocial agents make use of the linguistic channel, the communication protocol differs within the community. 这意味着尽管agent A都是固定的,不同的agent B和agent A会使用不同的language。(疑问在于有没有做 the same level of prosociality但不同agent的实验?随机性如何消除的?)文章使用的方法是计算不同agent的Spearman correlation。
Discussion
未来的有趣研究方向是Language能否在self-interested agent interacting中产生。Recent encouraging results by Crandall et al. (2018) show that communication can help agents cooperate. However, their signalling mechanism is heavily engineered: the speech acts are predefined and the consequences of the speech acts on the observed behaviour are deterministically hard-coded. It would be interesting to see whether a learning algorithm, such as Foerster et al. (2017), can discover the same result.