
Materials
- paper: “Attention Is All You Need”
- 知乎文章 “Transformer详解”
- blog “The Illustrated Transformer”, which is extremely helpful!!!
Model Architecture
Sequence Modeling问题简述为以下:
The encoder maps an input sequence of symbol representations $x = (x_1,\cdots,x_n)$ to a sequence of continuous representations $z = (z_1,\cdots,z_n)$. Given $z$, the decoder then generates an output sequence $y=(y_1, …, y_m)$ of symbols one element at a time.
encoder-decoder framework是auto-regressive的,也就是说当前生成的词是conditioned on the previously generated word (previously generated symbols as additional input when generating the next). 注意:虽然我们传统意义上使用encoder-decoder时,encoder往往将variable-length的input映射成fixed-length的向量(RNN中为最后一个hidden state),但是encoder在编码时已经生成了很多的中间结果构成$z = (z_1,\cdots,z_n)$ .
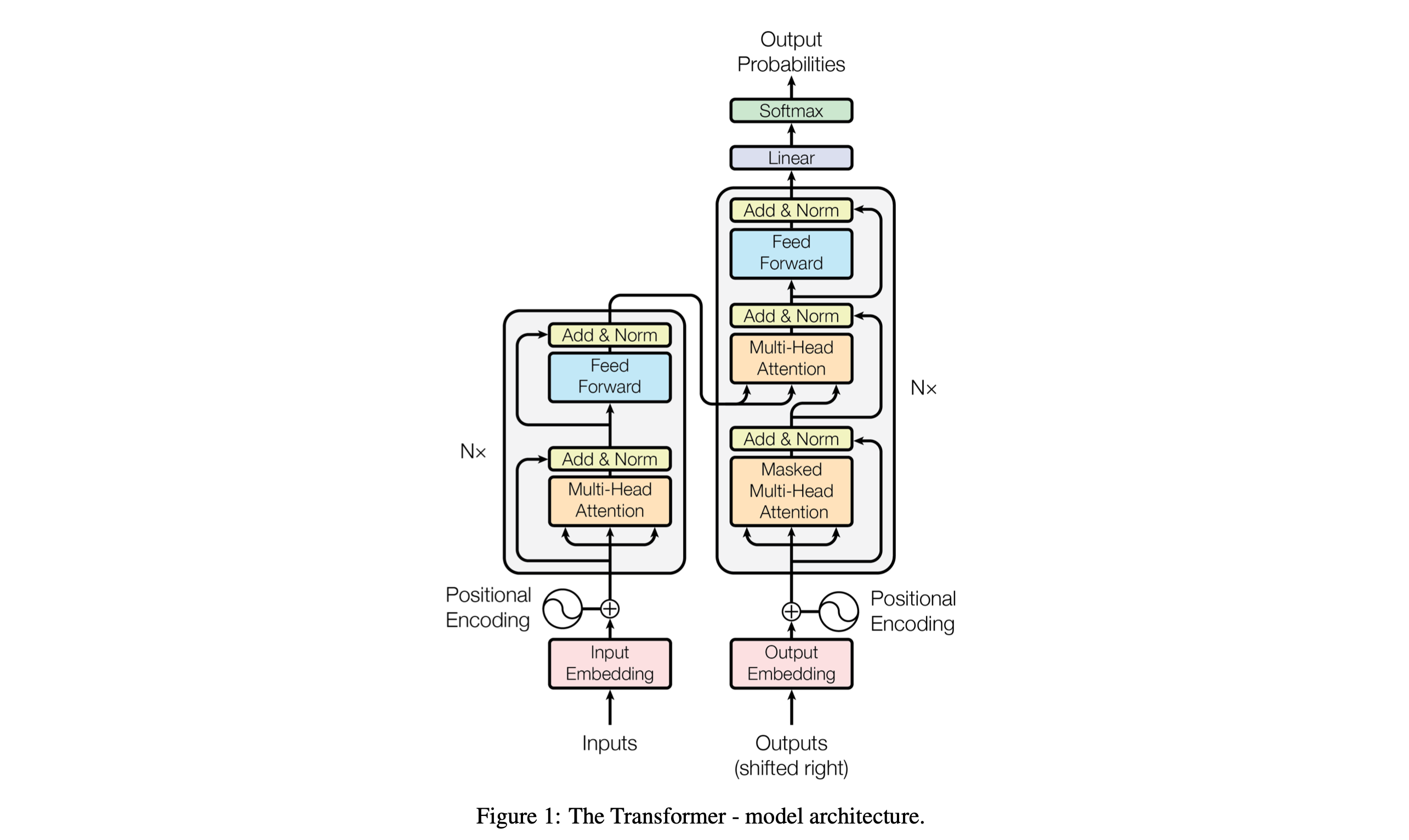
Transformer的模型如下图所示。
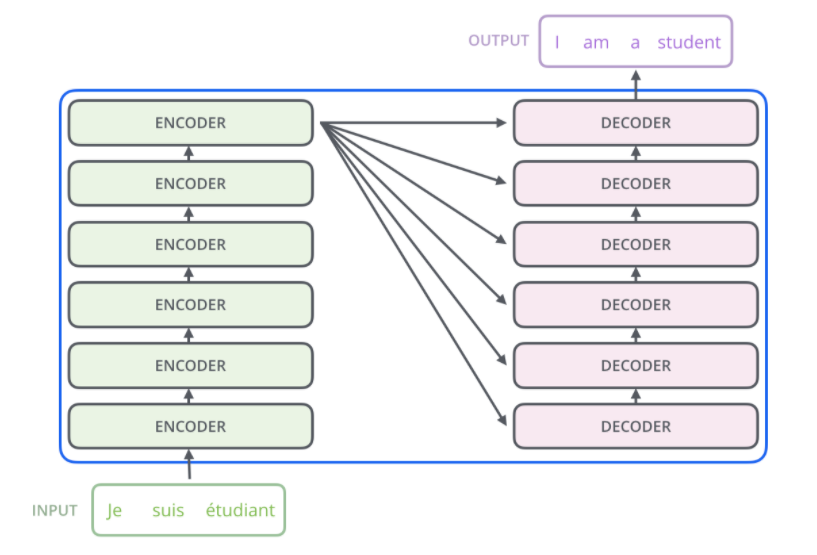
下面是blog中更加简洁但是能看得清flow的示意图,可以看到encoder最后一层的结果会作为每一层decoder的input。
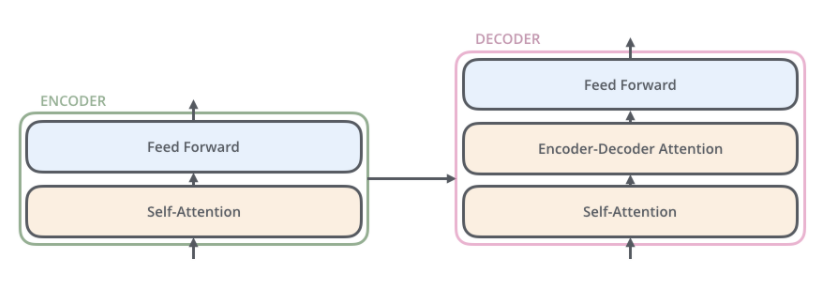
Encoder and Decoder Stacks
Encoder
由6层相同的layer组成,每层layer由3层sublayer组成。
第一层sublayer是multi-head self-attention;第二层是position-wise fully connected feed-forward network。
在两层之间加入了residual network的设计:
为了使residual成为可能,model的所有向量长度都是对齐的$d_\text{model} = 512$.
Encoder是可以完全并行化处理的,因为所有的input vector是全局可见的。
Decoder
- 由6层相同的layer组成,每层layer由3层sublayer组成。
- 在Encoder结构的基础上中间插入了一层multi-head self-attention.
We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
这一段话是理解Decoder过程的关键。首先要明确的是Transformer的encoding可以并行化,但是decoding确是auto-regressive的。而在Decoder中有两层不同的attention机制,包括了第一层的self-attention和第二层加入了encoder信息的attention机制。
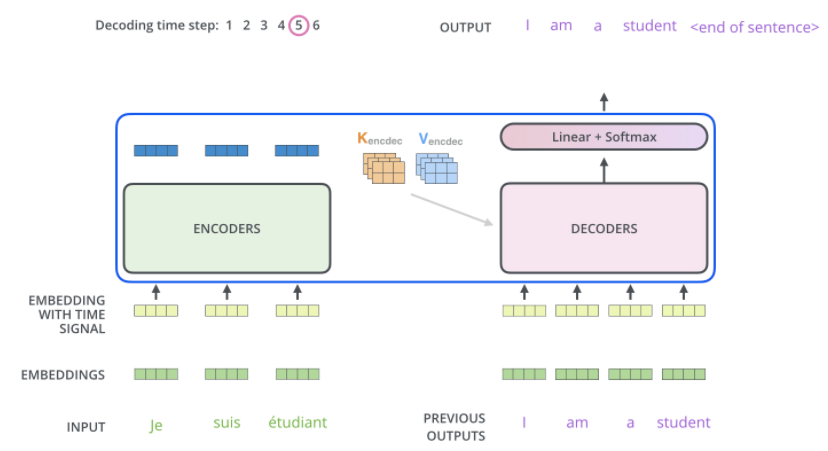
然后是最关键的,通常来说我们认为两个模块之间是以embedding的形式来进行信息的传递的,但是注意encoder产生出的结果是一个三元组(Query, Key, Value),其中Value就是我们通常意义上的embedding。而由于在decoder中也需要使用attention机制,所以自然地,将(Key, Value)都作为输出传给decoder。
假设当前为$i^{th}$ time step,从input一直到产生softmax输出分布的流程为:
- input为前$i-1$个output token embeddings, 这一点是通过mask机制来实现的
- input经过positional encoding得到embedding with positional signal
- input经过self-attention得到中间结果$z_1$(其中的QKV也是含参重新生成,而不是使用encoder产生的QKV)
- $z_1$利用encoder产生的$(K, V)$通过encoder-decoder attention得到$o_1$, which serves as input of the next decoder block.
- 经过若干个decoder模块之后,通过softmax产生输出的分布,取得$i$号位置的输出
Attention
Attention机制可以被看作是given a set of key-value pairs,将query映射到一个output上。output通常是weighted sum of the values, based on the similarity of the query-key pairs.
一层Attention运行流程如下:
- 假设input token sequence为$X = \{x_1, x_2, \cdots, x_n\}$ ,
- 将每一个token vector分别通过参数矩阵$W^Q, W^K, W^V$,得到以下:
- Query: $Q=\{q_1, q_2, \cdots, q_n\}$
- Key: $K=\{k_1, k_2, \cdots, k_n\}$
- Value: $V=\{v_1, v_2, \cdots, v_n\}$
- $Q,K$之间的dot product表示了词之间的关联系数,也就是attention机制赋予的权重
- 将权重和$V$进行加权平均,就得到了这一层encoding结果
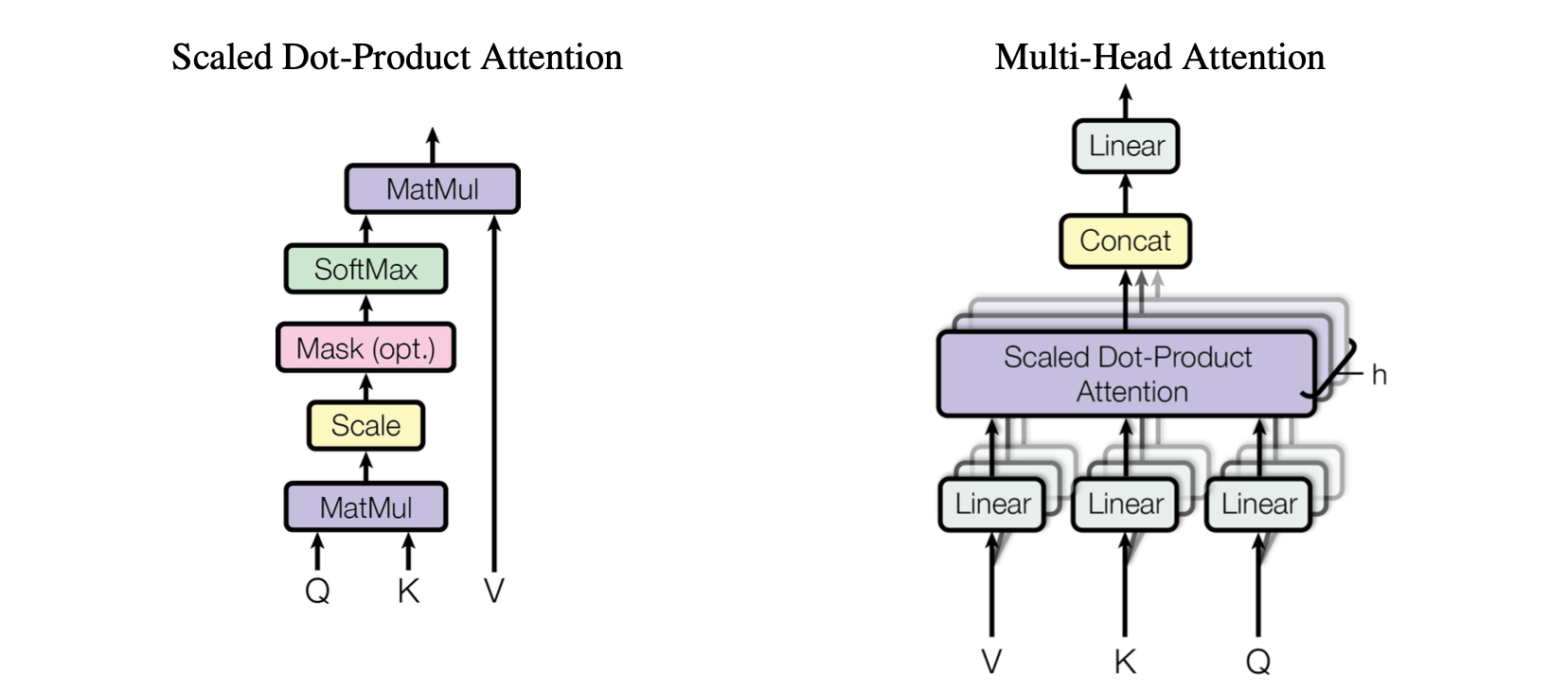
Scaled Dot-Product Attention
Scaled Dot-Product Attention 是本文使用的attention机制。In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix $Q$. The keys and values are also packed together into matrices $K$ and $V$. We compute the matrix of outputs as:
Multi-Head Attention
通过实验发现如果将$Q,K,V$这些向量分别线性映射(映射也是参数化的)到不同的空间,然后并行地计算Attention,最后concat并映射回原来的空间,将会非常有提升(见图)。这样的技术叫做Multi-Head Attention.
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
在本文中采用了 $h=8$ parallel attention layers,在不同head的空间中数据维数显著减小,提升了运算表现。
Position-wise Feed-Forward Networks
Feed-Forward Networks 定义为线性映射+RELU+线性映射:
Positional Encoding
如何加入当前位置的位置信息,作者给出了一个sine+cosine的函数:
其中$pos$为当前位置而$i$为当前embedding的dimension。这样的函数能够帮助编码模型的相对位置信息,因为对于一个固定的relative offset $k$,$PE_{pos+k}$能够被表示成$PE_{pos}$的线性函数($\sin(\lambda k)$以及$\cos(\lambda k)$为常数,根据三角展开式得到)。