
Materials
- paper “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”
- youtube “BERT Explained”
Motivation
BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks.
预训练模型在sentence-level和token-level tasks上都有很不错的表现。现存的预训练方法可以分为feature-based和fine-tuning:
- ELMo作为前者 uses task-specific architectures that include the pre-trained representations as additional features.
- The fine-tuning approach, such as the Generative Pre-trained Transformer (OpenAI GPT) introduces minimal task-specific parameters, and is trained on the downstream tasks by simply fine-tuning all pretrained parameters.
The two approaches share the same objective function during pre-training, where they use unidirectional language models to learn general language representations.
BERT采用“masked language model” (MLM) pre-training objective. The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context.
- We showed the importance of the bidirectional pre-training for language representations.
- We show that pre-trained representations reduce the need for many heavily-engineered task-specific architectures
- BERT advances the state of the art for eleven NLP tasks.
Model Architecture
BERT’s model architecture is a multi-layer bidirectional Transformer encoder based on the original implementation.
Input/Output Representations
因为BERT是一种预训练模型,所以需要匹配各种不同形式的输入输出。在BERT的训练中,一个sentence不是一个语义上的sentence,而只需要是arbitrary span of contiguous text. 而一个sequence可以是一个sentence也可以是两个放置在一起的sentence(例如在QA问题中的Question-Answer pair需要用到两个并置的sentence).
- The first token of every sequence is always a special classification token ([CLS]).
- Sentence pairs are packed together into a single sequence. We differentiate the sentences in two ways.
- We separate them with a special token ([SEP]).
- We add a learned embedding to every token indicating whether it belongs to sentence A or sentence B.
- 最终,将最后一层[CLS] token得到的hidden state标记为C,其余中间结果的final hidden states标记为$T_i \in \mathbb R^H$. 见下图左边pre-training部分。
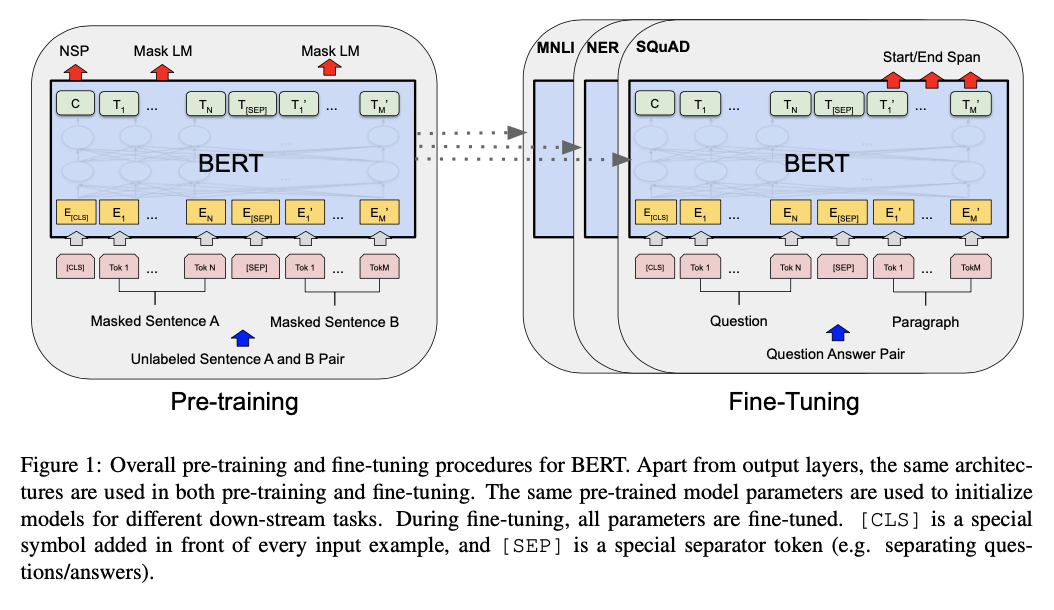
Pre-training BERT
采用两个Unsupervised Tasks对BERT进行训练。
Task #1: Masked LM
In order to train a deep bidirectional representation, we simply mask some percentage of the input tokens at random, and then predict those masked tokens. We refer to this procedure as a “masked LM” (MLM), although it is often referred to as a Cloze task in the literature. 在BERT中,被mask掉的位置会送入一个mask token,然后在输出层输出softmax的概率分布。训练时BERT采取的是随机mask掉15%的token,但是这样会造成所谓”mismatch”:因为mask token不会在fine-tuning阶段出现。为了缓解这个问题,文章将已经选中的token再进行:
- 80%几率真实替换为mask token
- 10%几率替换为random token
- 10%几率保留原token
Task #2: Next Sentence Prediction (NSP)
这个任务的动机在于对于很多的任务,例如Question Answering / Natural Language Inference等,需要探究句子之间的关系。选择进入模型的sentence来进行NSP任务时,句子B有50%的概率选择非A的next,同时标注为NonNext,在这个任务下,最后的C就是用来判断是否为next sentence的标志。
Pre-training Data
一共使用了3个大数据集进行非监督的训练,包括BooksCorpus (800M words), English Wikipedia (2,500M words), Billion Word Benchmark to extract long contiguous sequences.
Fine-tuning BERT
For each task, we simply plug in the task-specific inputs and outputs into BERT and fine-tune all the parameters end-to-end. (A, B) sentence input可以适应各种样式的input:
- 形如QA任务的输入就是question-passage pair
- 如果是单一语句输入就是degenerate text-$\empty$ pair
At the output, the token representations are fed into an output layer for token-level tasks, such as sequence tagging or question answering, and the [CLS] representation is fed into an output layer for classification, such as entailment or sentiment analysis.