Materials
- paper “Unsupervised Inductive Graph-Level Representation Learning via Graph-Graph Proximity”
- quora “Difference between transductive/inductive learning - post of Ramashish Gaurav”
Transductive/inductive Learning
- Transductive learning 是可以提前见到unlabelled test set并且利用这些数据来达到更好的表现。
- Inductive learning 则完全看不见test data,需要在training data上训练出一个模型,将这个模型运用到test data得到结果。
Motivation
该工作提出了一个general framework从而使得在unsupervised data上能够做graph-level inductive embedding. 文章称“当前工作一般都隐性地假设了好的node embedding能够导致好的graph embedding”,但这只考虑了图内信息而没有考虑图间信息(intra-graph information v.s. inter-graph information),因此需要进一步改进,在最近关于graph proximity modeling工作的基础上,文章提出了一个framework: UGraphEMB. 因为保留了图拓扑结构的信息,所以在一些基于图的下游任务(classification, similarity ranking, visualization)中有比较好的效果。
Model Architecture
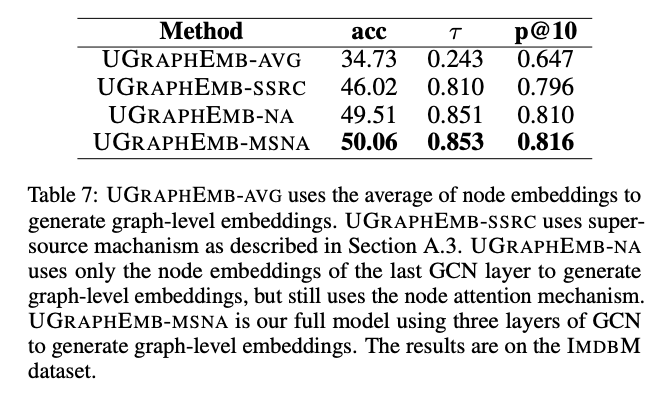
在graph-level embedding生成过程中,需要首先生成node embedding,随后需要将node embedding通过聚合方式得到graph embedding,那么在这个过程中我们给一个人为的训练目标:也就是graph proximity在映射结束之后还是能够和原先的proximity保持一致,这部分预训练结束之后就可以将model运用到下游任务中。整个过程如下图所示。
Node Embedding Generation
首先在Node Embedding的部分,文章采用了GIN。虽然没有在文章中明确说GIN是能够最大程度地保留图结构信息的aggregation function,但是作者直接提到使用这个模型是因为这个模型是那个时候的SOTA模型,GIN的聚合函数如下:
Graph Embedding Generation
作者在这里表示,虽然Graph Embedding Generation可以使用一些非常简单的aggregation function,但是他们认为,因为目标是将graph映射到一个保留了他们相似度的空间中,the graph embedding generation model should:
- Capture structural difference at multiple scales. 文章论述这一点:”However, after many neighbor aggregation layers, the learned embeddings could be too coarse to capture the structural difference in small local regions between two similar graphs.“
- Be adaptive to different graph proximity metrics. 这一点要求aggregation中必须要含有可学习的参数。
从而本文提出了一个新的Multi-Scale Node Attention (MSNA) mechanism. 首先用 $U_{\mathcal{G}} \in \mathbb{R}^{N \times D}$ 来表示graph $\mathcal{G}$ 的input node embeddings. The graph level embedding is obtained as follows:
Instead of only using the node embeddings generated by the last neighbor aggregation layer, we use the node embeddings generated by each of the K neighbor aggregation layers.
第K层的ATT函数定义式如下:
其中$\Theta$表示第K层的参数,从而during the genera-tion of graph-level embeddings, the attention weight assigned to each node should be adaptive to the graph proximity metric.
Graph Proximity
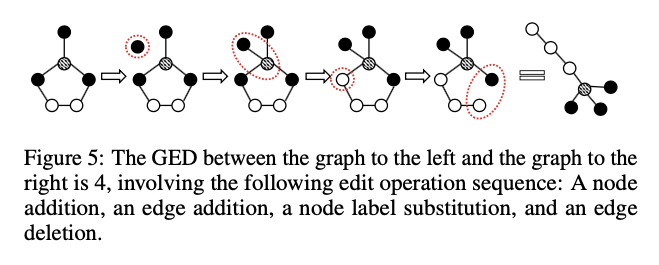
这一层简单介绍了可以用作Unsupervised Representation Learning的优化函数的graph-graph proximity,常见的有GED (Graph Edit Distance) 和 MCS (Maximum Common Subgraph) 。本文的描述非常严谨:“In this paper, we used GED as an example metric to demonstrate UGraphEMB. ”图编辑距离指的是对图进行编辑的最少步数转变成另一个图,其中一次编辑指的是”an insertion/deletion of a node/edge, or relabelling a node.”
为了在训练时保留高维数据点(Graph)的两两距离,文章采用了Multidimensional Scaling (MDS)的数据降维方法,这个方法的核心想法是将数据集中的点map到低维空间中,同时保留数据点两两之间的距离。这一点是通过最小化以下目标函数达到的:
用采样+数学期望的方式来表达这个函数:
如果是图之间的距离是它们的相似度,那么我们可以直接用内积的形式来计算两个图向量的距离:
Experiments
文章在3个任务的5个数据集上进行了该方法验证。对于这个预训练方法,作为读者我们想要问的问题是:
- pre-trained graph embeddings 能给下游任务带来多少提升?是否能够加快下游任务的训练速度?
- 和当前的graph representation learning algorithms相比是否有显著的提升?
- Ablation Study需要涵盖:
- 不同的Node Embedding Module有什么差别?
- 如果不采用Multihead-Attention机制会有怎样的变化?
- 数据集中有没有一些Same structure, Disparate meaning的graph-pair?尤其对于小图来说?这样来说graph-graph proximity是不是就不make sense了?
Classification
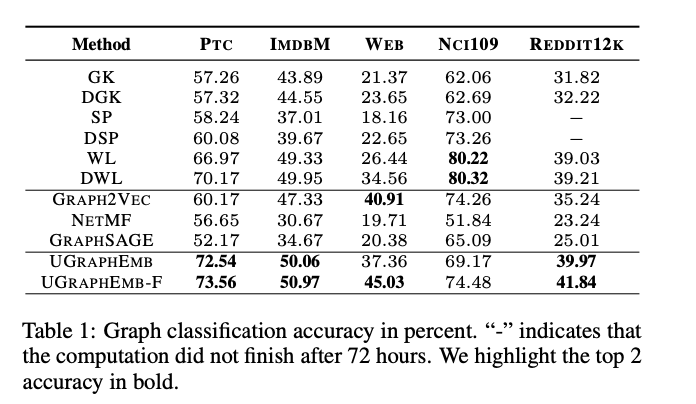
汇报了classification accuracy,如下表。
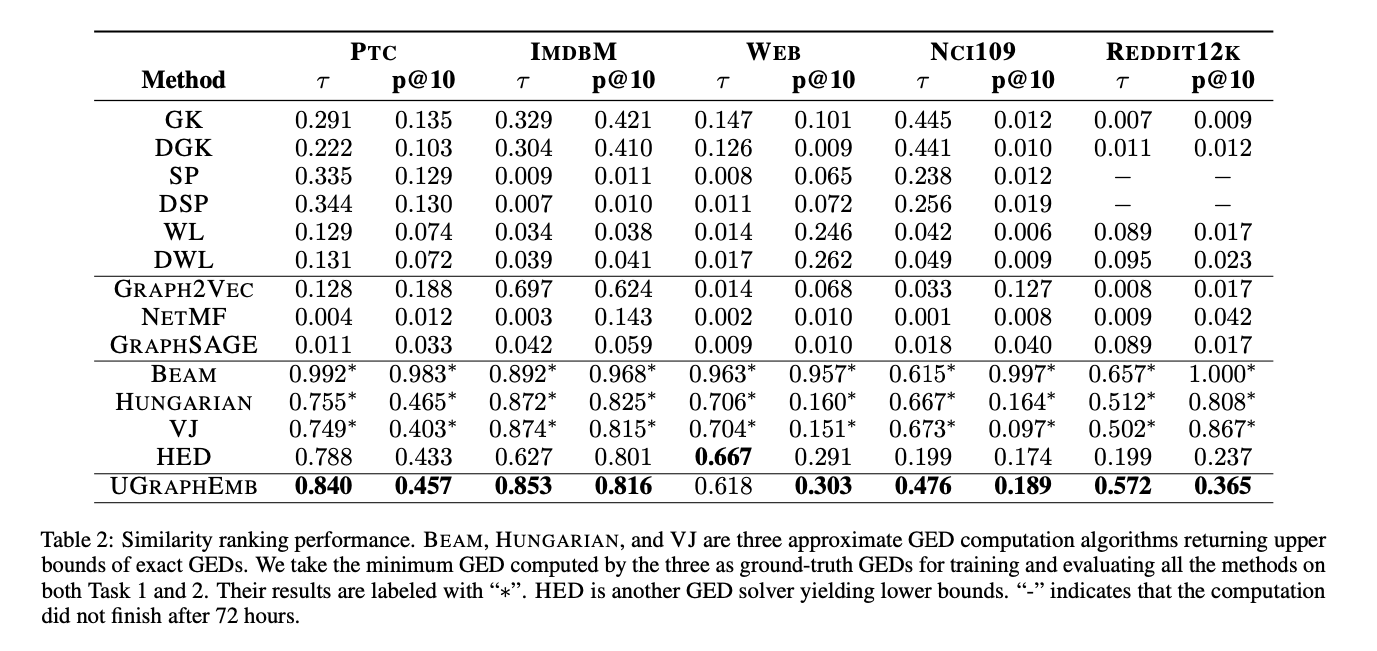
Similarity Ranking
汇报了Kendall’s Rank Correlation Coefficient ($\tau$) 和 precision at 10 (p@10),如下表。
Ebedding Visualization
将graph embedding learned by all the methods into the visualization tool t-SNE, 得到了以下可视化结果,拥有相同的子图结构的图被更好地分在了同一个cluster中,这大概率是使用graph-graph proximity的结果。

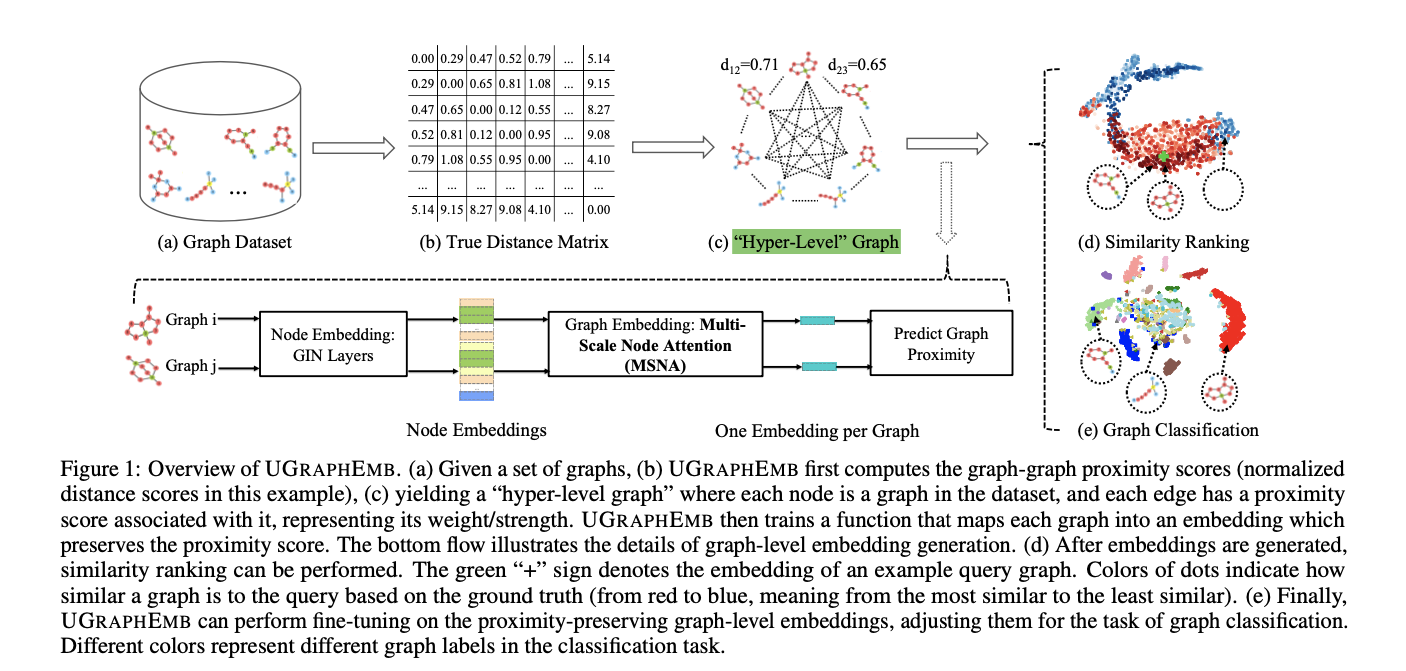
MSNA Ablation Study