
Materials
Basic Gradient Descent
从batch大小的角度来看,GD方法可以分为以下三类:
- Batch Gradient Descent: 整个数据集都参与gradient的计算
- Stochastic Gradient Descent: 每次计算gradient时都只从数据集中sample 1个data
- Mini-batch Stochastic Gradient Descent: 每次sample一个小的batch进行gradient计算
通常意义上我们说的SGD都指的是mini-batch SGD. 如下式,其中 $\eta$ 表示学习率
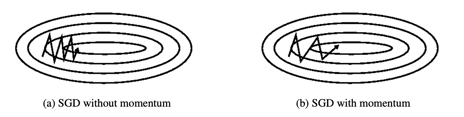
Momentum
Momentum想要避免前后两个time step之间太过于剧烈的gradient变动,采用了CS中常见的平滑策略。以下的示例展示了这种平滑策略:假设a是不断在0, 1之间震荡的gradient,那么变量b采取以下等式
则得到以下经过平滑后的曲线效果
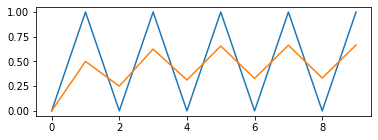
从而给出了平滑gradient的momentum.
Adagrad
Adagrad希望能够做到对于每个参数的更新都能够做到自适应,而不是统一使用一个学习率$\eta$. 在第$t+1$个时间步第$i$个参数$\theta_{t,i}$的更新法则为
其中参数更新自适应的scale $G_{t,ii}$ 表示的是该参数在之前时间步对应gradient的平方和
向量化后得到
Adadelta
Adagrad的最大问题就在于learning rate随着time step的增加不可避免地diminish. 为了缓解这个问题,Adadelta保持了一个记录过去gradient的窗口。但是在内存中显式地保存过去$w$个gradient矩阵并不是特别理想的操作,为此Adadelta采用了类似于Momentum的平滑方法
取$\rho=0.5$同时再求根就得到了RMS(均方根),则得到了RMSprop方法
Adam
Adam同时想要达到Adaptive Learning Rate和Momentum的平滑化。首先定义gradient的两阶的近似,
接着为了纠正这两个近似的bias,
最终的参数更新按照以下
LARS
https://github.com/pytorch/pytorch/issues/18414: It mentions that ‘bn’ and ‘bias’ should not be affected by lars.
https://github.com/kakaobrain/torchlars: pytorch implementation of the LARS optimizer, failed here.