
Materials
Motivation
对于人类,同一事物在不同sensory channel的信息是高度相关的. We study this hypothesis under the framework of multiview contrastive learning, where we learn a representation that aims to maximize mutual information between different views of the same scene but is otherwise compact.
Structure of Introduction
- Autoencoders treat bits equally.
- We revisit the classic hypothesis that the good bits are the ones that are shared between multiple views of the world. This hypothesis corresponds to the inductive bias that the way you view a scene should not affect its semantics.
- Our goal is therefore to learn representations that capture information shared between multiple sensory channels but that are otherwise compact (i.e. discard channel-specific nuisance factors).
- Our main contribution is to set up a framework to extend these ideas to any number of views.
Method
文章从Multiview的角度将两大类方法进行了对比,分别为Predictive Learning和Contrastive Learning.
Predictive Learning
Autoencoder方法被归为Predictive Learning的范畴中。这类方法最大的问题在于其优化目标objective假设了每个pixel之间是相互独立的,thereby reducing their ability to model correlations or complex structure. 为什么叫predictive learning呢,是因为在Multiview的setting下,我们希望建立一个从view1->representation->view2的映射,最小化这个预测之间的loss. 这个形式和autoencoder有些类似,关于multiview predictive learning和autoencoder之间的关系,我们做以下图示进行说明:
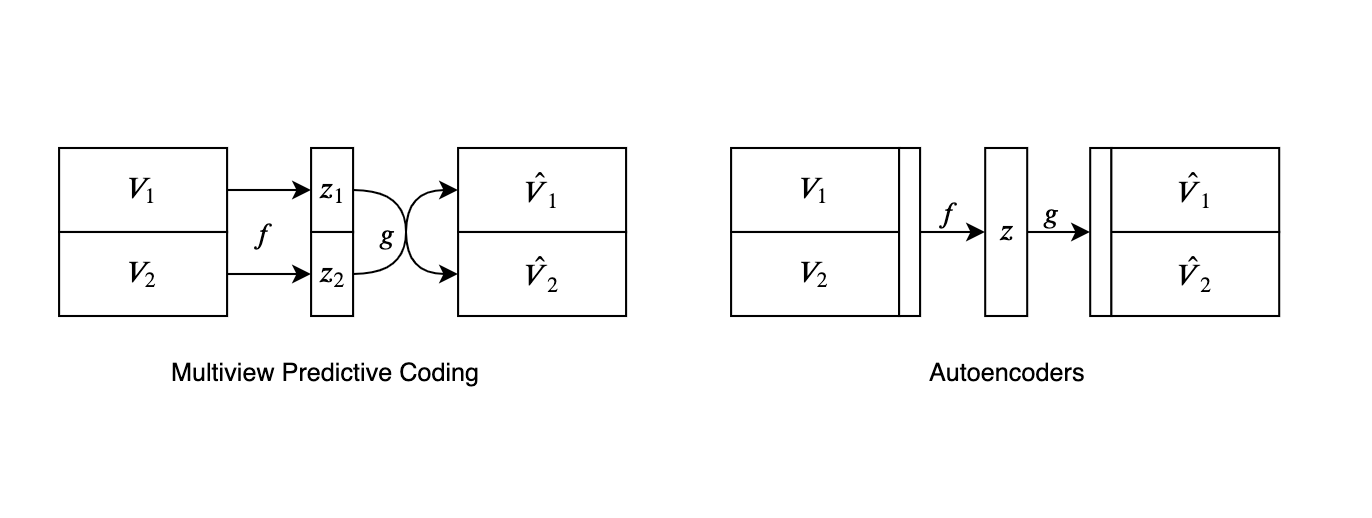
其实在这样的角度理解multiview predictive coding,就是不同view之间不能够有信息沟通。相当于我们在AE的架构上做了更多的locality的限制,同时认为不同view之间在信息量上是等价的(能够从一个view推测出另一个view),而该篇工作就建立在这个假设的进一步发展上:
The good bits are the ones that are shared between multiple views of the world.
因此使用Mutual Information来最优化不同view之间共享的信息就成了该篇工作的重点和亮点。
Contrastive Learning
Multiview Contrastive Learning的基本思想是:将同一个样本的不同view为一个正样本对$\left\{v_{1}^{i}, v_{2}^{i}\right\}_{i=1}^{N}$,对于第i个样本我们能够构造不同样本的不同view为一个负样本对$\left\{v_{1}^{i}, v_{2}^{j}\right\}_{j=1}^{K}$。通过训练一个critic function $h_\theta$来区分正负样本对,从而得到representation. 构造contrast loss为以下:
从而计算$V_1$和$V_2$之间的contrast loss为:
对称化两个view之间的loss:
对于Multiview的setting,作者还给出了两种经常遇到的情况,分别是view中有一个Core View和全连接view的情况。
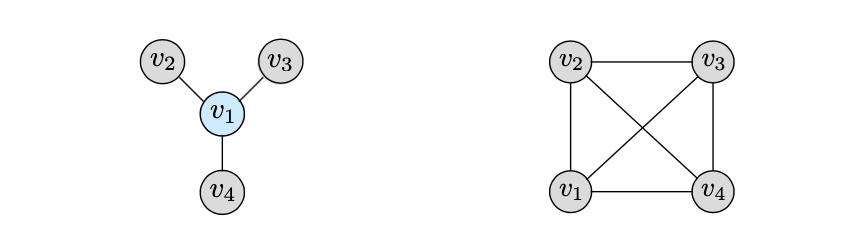
根据以上分别可以构造两个Loss function:
Experiments
文章一共做了三组实验:
- Two established image representation learning benchmarks: ImageNet and STL-10
- Video representation learning tasks with 2 views: image and optical flow modalities
- More than 2 views.
How does mutual information affect representation quality?
文章认为,Mutual Information Maximization不是让CMC成功的关键,关键是在于CMC背后关于representation的假设:“好的信息应该在不同的view之间被共享”,从而最大化不同view之间representation的MI,才能导致好的representation.
文章在高清2K的图片中random crop $64\times 64$的patch来进行Mutual Informatio之间的训练,唯一变量是patch之间间隔的pixel距离,通过两个view之间的MI estimation的差距来比较MI对最终downstream classification的影响,结果如下右图所示(左图表示的不同的RGB通道之间的关联,结果有些违反常识).
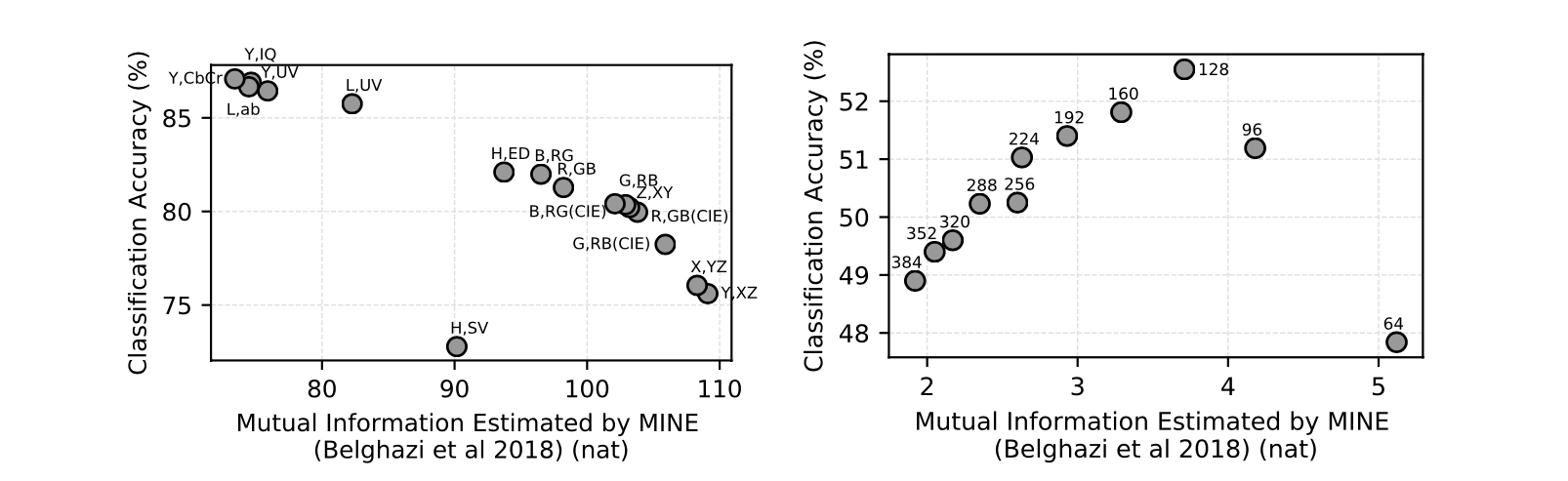
根据右图显示的结果,作者得出结论:
Here we see that views with too little or too much MI perform worse; a sweet spot in the middle exists which gives the best representation. That there exists such a sweet spot should be expected. If two views share no information, then, in principle, there is no incentive for CMC to learn anything. If two views share all their information, no nuisances are discarded and we arrive back at something akin to an autoencoder or generative model, that simply tries to represent all the bits in the multiview data.
These experiments demonstrate that the relationship between mutual information and representation quality is meaningful but not direct. Selecting optimal views, which just share relevant signal, may be a fruitful direction for future research.