Materials
- ICLR-2010 paper “Discriminative Clustering by Regularized Information Maximization”.
- ICLR-2020 paper “On Mutual Information Maximization for Representation Learning”.
Motivation
本文是采用MI来做Unsupervised Discriminative Clustering的工作,在”On Mutual Information Maximization for Representation Learning”中被提到,其中的表述如下:
It is folklore knowledge that maximizing MI does not necessarily lead to useful representations. Already Linsker (1988) talks in his seminal work about constraints, while a manifestation of the problem in clustering approaches using MI criteria has been brought up by Bridle et al. (1992) and subsequently addressed using regularization by Krause et al. (2010).
我们想要探究的是为什么maximizing MI不能够带来下游任务表现的提升?虽然前人的工作已经经验性地展示了这一点:MI的优化和下游任务表现的提升是disproportional的,通过提供constraints使得MI作为一个有效的目标,那么什么样的constraint才是好的constraint?设计一个新的constraint需要遵守怎样的guideline?这些也是我们想要研究的方向。这篇添加了regularization的工作可能是一个比较好的起始点。
这篇文章的动机在于当前的clustering方法没有很好地引入probabilistic model, 因此文章:
We propose a principled probabilistic approach to discriminative clustering, by formalizing the problem as unsupervised learning of a conditional probabilistic model.
We identify two fundamental, competing quantities, class balance and class separation, and develop an information theoretic objective function which trades off these quantities.
Our approach corresponds to maximizing mutual information between the empirical distribution on the inputs and the induced label distribution, regularized by a complexity penalty. Thus, we call our approach Regularized Information Maximization (RIM).
Methods
Discriminative Clustering
给定数据集$X$,目标是学习到一个conditional model $p(y|x, W)$ with parameters $W$ which predicts a distribution over label values $y \in \{1,\cdots,K\}$ given an input vector $x$.
Information Maximization
将Information Maximization方法应用到unsupervised clustering中不需要显示得定义cluster number. 同时因为最终的representation就是离散的类别标签,所以我们可以直接估计input-label两者的MI. 以下是作者论述构建出MI作为优化目标的clustering method.
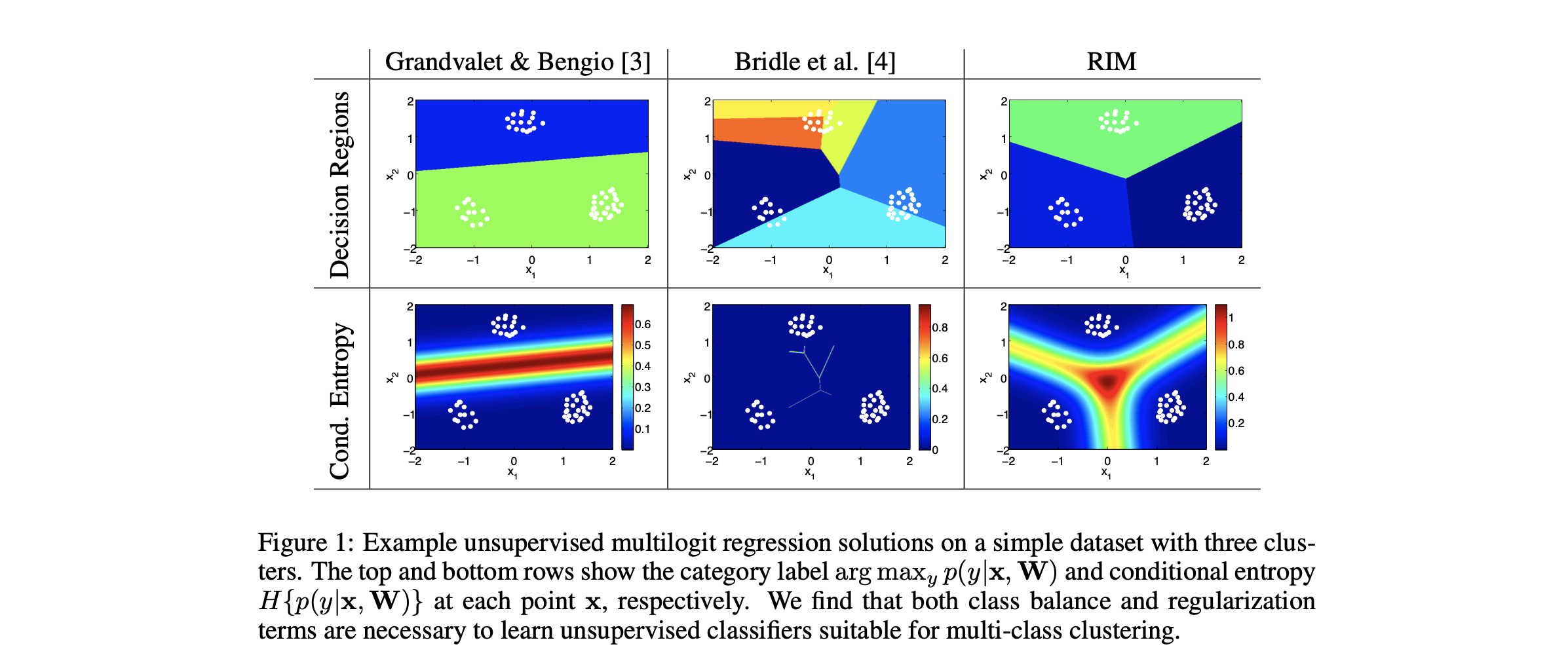
首先,discriminative clustering方法的第一个原则是不希望在数据分布密集的地方划分decision boundary. 前人的工作说明了conditional entropy term $-\frac{1}{N} \sum_{i} H\left\{p\left(y | \mathbf{x}_{i}, \mathbf{W}\right)\right\}$ very effectively captures the cluster assumption when training probabilistic classifiers with partial labels.
但是仅仅优化conditional entropy也是不够的。我们知道降低conditional entropy的目标是希望我们probabilistic model对于自己分类结果更加“确定”. 而因为我们的聚类方法没有对$K$的数量进行限制,所以”simply removing decision boundaries”,将所有的样本都归为同一类就能够骗过我们的优化目标,而得到非常糟糕的discriminative model.
为了避免以上提到的degenerate solution, 文章提出要做到类间平衡 (class balance). 计算每个类别的marginal label distribution,我们得到:
所以类间平衡的要点在于使每个类别尽量能够均匀地分布,即最大化类分布的熵。结合两者,我们得到了最大化MI的优化目标:
在clustering任务中,前人也已经发现了这个优化目标有trivial solution:”However, they note that $I_{\mathbf{W}}\{y ; \mathbf{x}\}$ may be trivially maximized by a conditional model that classifies each data point $x_i$ into its own category $y_i$, and that classifiers trained with this objective tend to fragment the data into a large number of categories”.
Regularized Information Maximization
在此基础上,文章提出了使用一个正则项 $R(W;\lambda)$ 对MI进行约束:This term penalizes conditional models with complex decision boundaries in order to yield sensible clustering solutions. Our objective function is
在Multilogit-regression任务中文章给出了参数的模作为正则项。本质上正则项就是为了防止过多的decision boundary被发现从而约束RIM的类别数量,一般来说,$\lambda$ 越大类数越小。
Experimental Results