
Materials
Method Description
Given a pair of images sharing some attributes, we aim to create a low-dimensional representation which is split into two parts: a shared representation that captures the common information between the images and an exclusive representation that contains the specific information of each image.
Two stages of training. First, the shared representation is learned via cross mutual information estimation and maximization. Secondly, mutual information maximization is performed to learn the exclusive representation while minimizing the mutual information between the shared and exclusive representations.
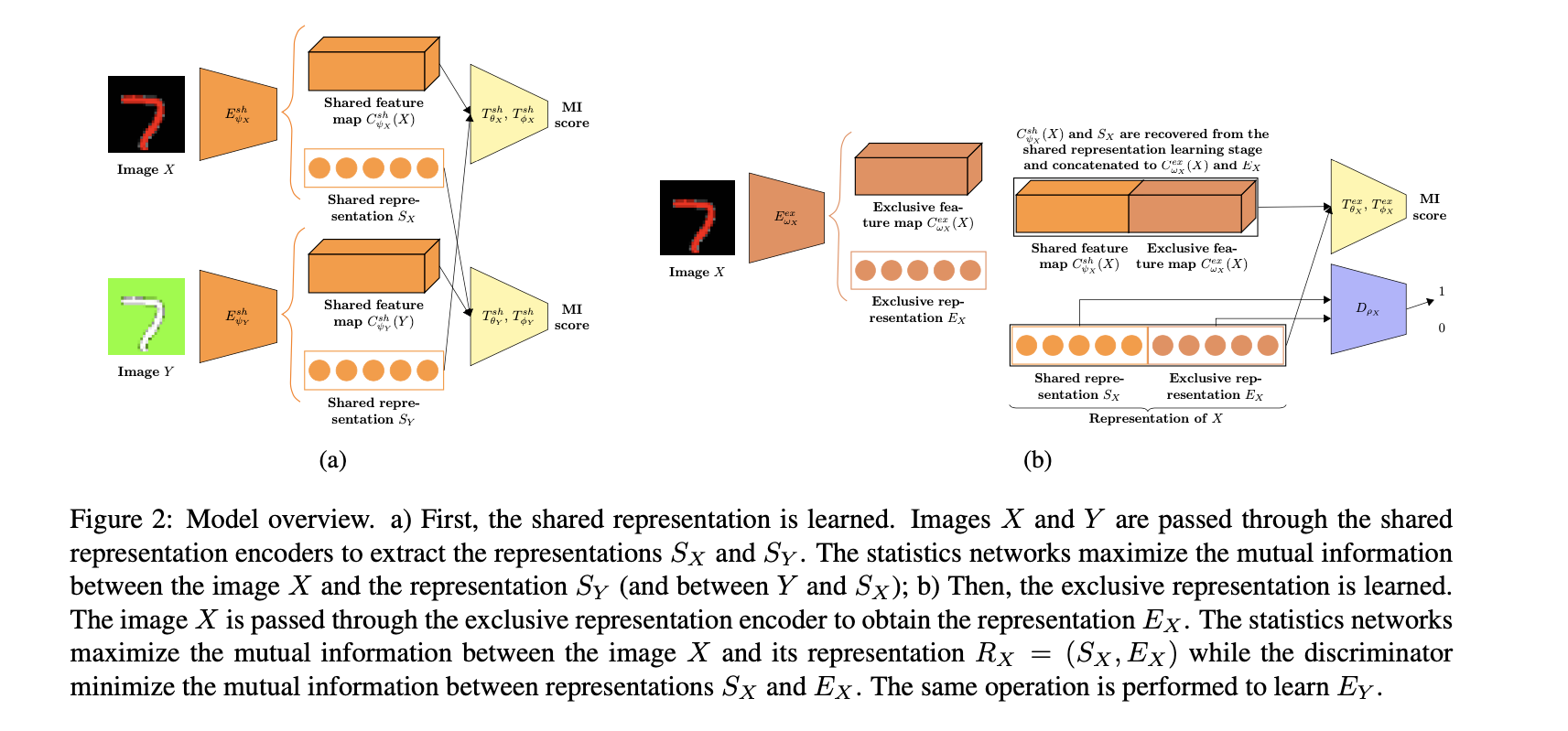
两个样本的representation包括了shared information and exclusive information.
首先在训练的第一阶段,我们希望他们的shared representation能够尽量相同,于是文章采用了叫做cross mutual information maximization的方法,将 (sample,local patch, representation) 三元组 $(X, C_X, R_X)$ 和另一个样本的三元组$(Y, C_Y, R_Y)$进行”交叉互信息最大化”:
接着,我们希望他们的exclusive representation能尽量不同。于是文章在第二阶段,固定了生成shared representation的模型参数,同时在两方面训练网络:最大化合并之后的representation的global/local MI,同时最小化exclusive/shared MI.
Experiments
关于实验的和整个任务的setting,有以下的问题和作者进行交流。
Question
Dear Eduardo Hugo Sanchez,
After reading your wonderful paper “Learning Disentangled Representations via Mutual Information Estimation”, I have one question regarding the setup of your training procedure, which is:
How do you decide between which two images the MI is maximized during training? Say in Colorful MNIST, if you put the images of the same digit together and follow your obejective, then can I conclude that you’re actually telling the model to learn a (linear, in some cases) seperable representation regarding the digit classification? Below is how I come to this conclusion:
If we are maximizing the MI between all the images containing the same digit, then during the process of MI maximization, we will shuffle the whole batch of the data in order to form the negative samples, which will be feed into the critic function. Since the critic function has to distinguish the samples like (X,Y)=(black7, red7) and the shuffled samples like (X,Y’)=(black7, yellow10), we are explicitly telling the model to classify the digits.
If we train the whole network in a totally unsupervised way, i.e., training sample pairs like (X,Y)=(black7, yellow10) are randomly showing up asking the model to learn the shared information between them, how the method is able to learn the disentangled representations is really confusing me…
Furthermore, did you do the ablation study of the “cross mutual information maximization” technique? How did it go?