
Materials
- paper “InfoGraph - Unsupervised and Semi-Supervised Graph-Level Representation Learning via Mutual Information Maximization”
- openreview of the paper
- my blog about JS divergence
- paper “Learning Deep Representations by Mutual Information Estimation and Maximization”
Motivation
Kernel-based methods没有generalization的能力,同时无监督和半监督的setting非常promising。We maximize the mutual information between the graph-level representation and the representations of substructures of different scales (e.g., nodes, edges, triangles).
Logic of Introduction
- Graph is important, providing diverse structured data.
- Representation learning of the entire graph is a rising field of the community.
- Extant methods are mostly supervised, which is bad since labeling data is costly.
- one way to solve it is through semi-supervised learning.
- or better, by unsupervised learning.
- Introducing representation learning for graphs. They are not to one’s satisfaction since:
- many don’t provide graph embedding explicitly.
- kernels are handcrafted.
- Inspired by the method of maximizing mutual information, we propose InfoGraph.
- Our contribution.
Related Work
- The graph kernel $K(G1, G2)$ is defined based on the frequency of each sub-structure appearing in $G_1$ and $G_2$ respectively. Namely, $K(G_1, G_2) = \left
- An important approach for unsupervised representation learning is to train an encoder to be contrastive between representations that capture statistical dependencies of interest and those that do not.
- Mean Teacher adds a loss term which encourages the distance between the original network’s output and the teacher’s output to be small. The teacher’s predictions are made using an exponential moving average of parameters from previous training steps.
Model Architecture
Problem Definition

该工作的Unsupervised Learning是属于transductive representation learning. 也就是说在遇到一个新的graph时没有办法生成该graph的representation. 而Semi-supervised Learning更符合inductive learning的模式:也就是学习一个模型,在遇到新的未标注数据时可以替他们生成embedding,和之前的graph-grraph proximity比较起来相对弱了一些。
InfoGraph
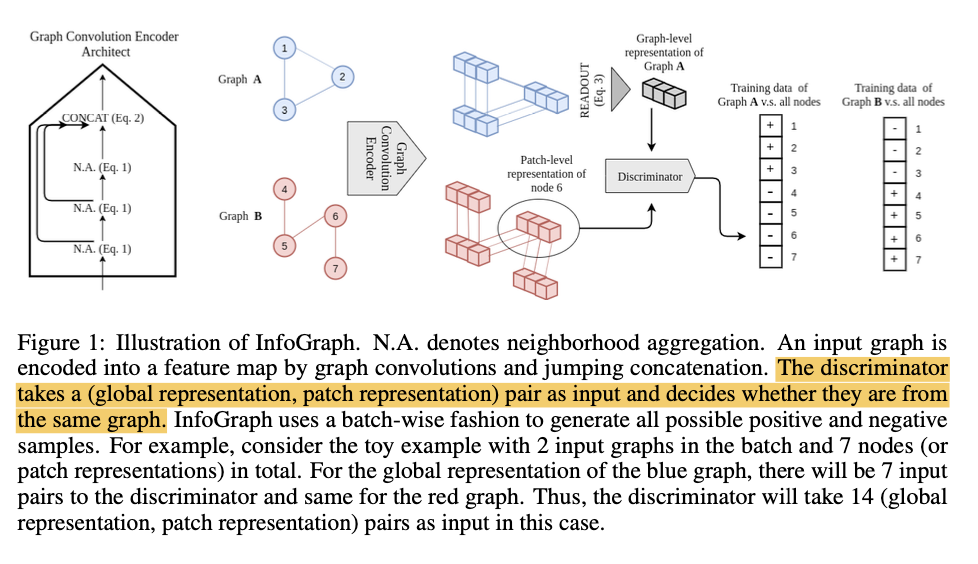
利用GNN不断aggregate neighboring node features的特性,文章将这些feature称作“patch representations”,同时GNN采用Readout function将patch representations映射成一个fixed-length graph-level representation:
通过K层GNN,可以将每一层的representation concat起来,这样就得到了“of different scales”的representation:
然后定义MI estimator on global/local pairs, maximizing the estimated MI over the given dataset $\mathbf{G}:=\left\{G_{j} \right\}_{j=1}^{N}$:
同时采用Jensen-Shannon MI estimator:
In practice, we generate negative samples using all possible combinations of global and local patch representations across all graph instances in a batch.
Experiments
For classification, 6 commonly used datasets.
- MUTAG
- PTC
- REDDIT-BINARY
- REDDIT-MULTI-5K
- IMDB-BINARY
- IMDB-MULTI
For semi-supervised setting, QM9 dataset.